非正規分布の工程能力計算: ISO22514-4、22514-2に準拠
工程能力:Cp/Cpk No.1で真直度等の幾何公差はLSLが自然限界となる事を説明しました。このようなデータはプラス方向にのみバラつきます。
実はこのようなデータは分布の形が正規分布に沿いません。
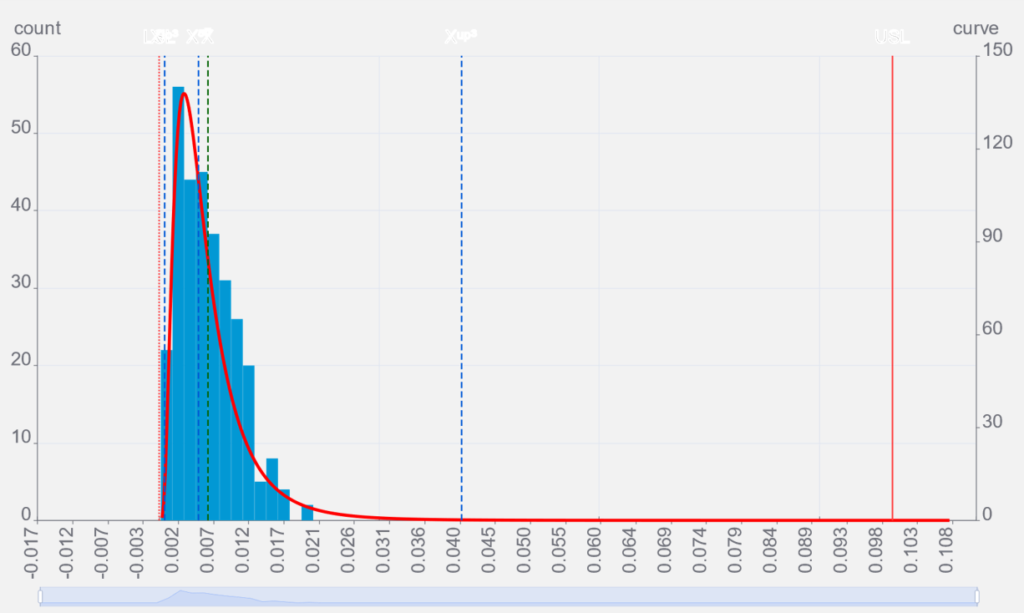
フィットしない分布モデルの影響
正規分布を当てはめて、工程能力を計算すると、実際にはデータが発生しない0以下の部分にもデータが発生するという予測を行ってしまう事になり、実態と合わなくなります。
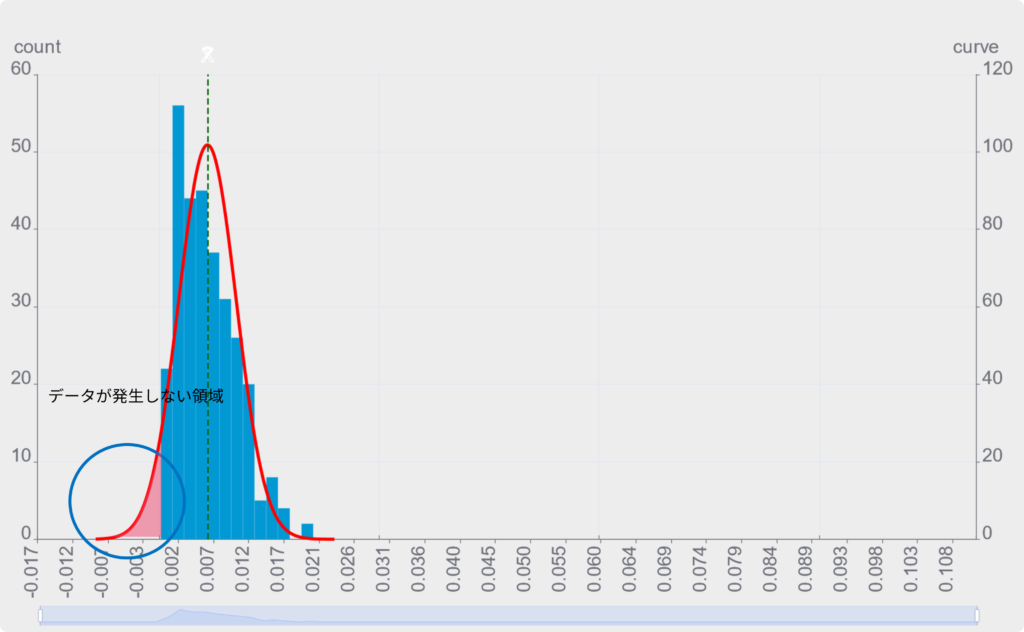
正規分布の特徴
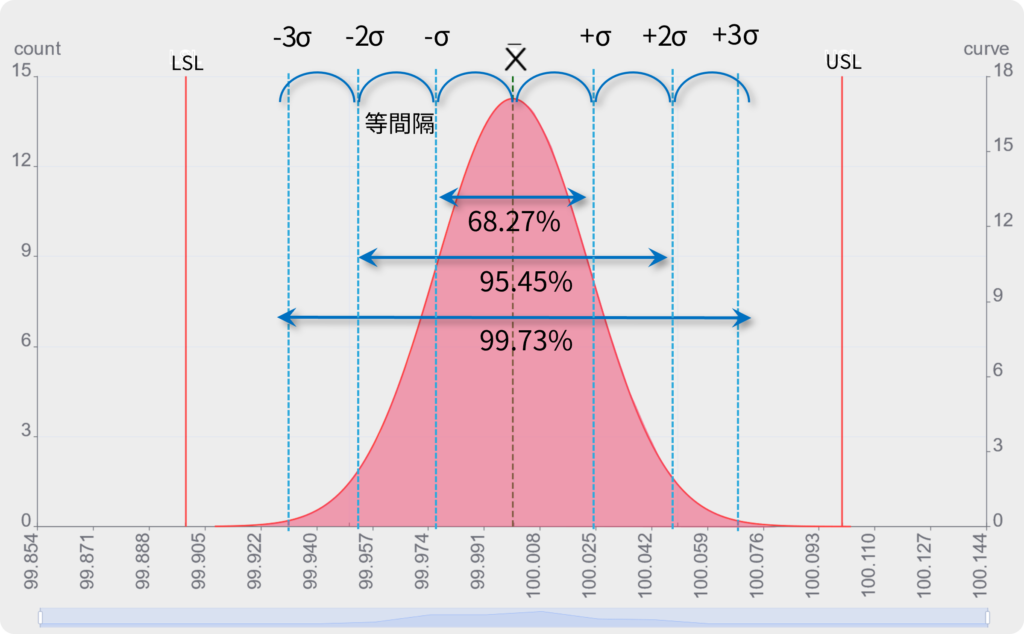
これまで説明した工程能力計算は全てデータが正規分布になる事を前提にしています。実は正規分布は多数の分布曲線の中でも特殊ケースで、標準偏差(σ)を使って工程能力を簡単に算出できるという特性があります。これは1σ、2σ、3σの間隔が等間隔である事が前提になっています。
非正規分布の特徴
非正規分布の場合、これまで工程能力算出に使用してきた標準偏差(σ)を使う事ができません。
■
下図のように非正規分布の場合、標準偏差を算出しても、±3σが99.73%の範囲にならない。
■
非正規分布では1σ、2σ、3σに相当する範囲の間隔が一定ではない。
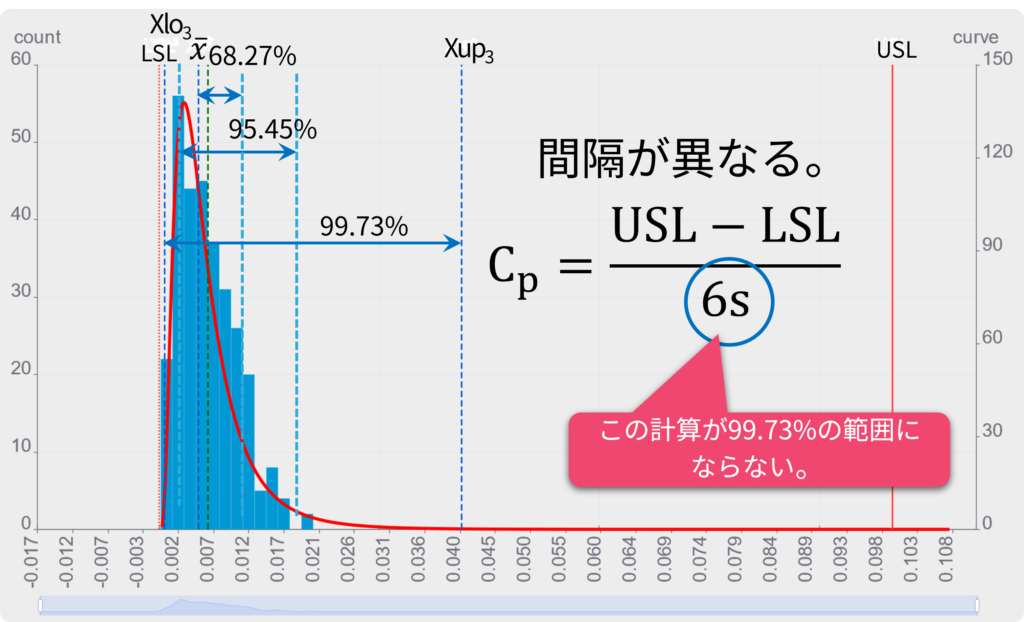
工程能力計算の意味
非正規分布の場合はσを使った工程能力計算が出来ません。しかし、ここでもう一度工程能力の計算式の意味を思い出してください。
6σの部分はバラつき範囲(99.73%のデータが存在する範囲)を意味します。
つまり、標準偏差に頼ることなく、この99.73%の領域を示す-3σ、+3σ相当の位置が分かればこの式は成り立つ事になります。
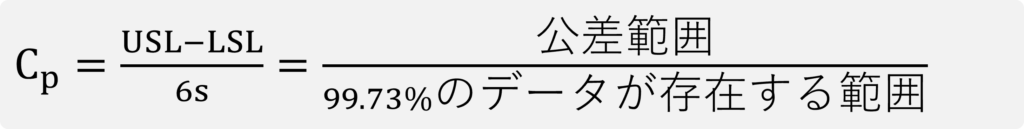
分位点
理屈がわかっても、実際に非正規分布の±3σ相当の範囲を算出するのは簡単ではありません。iNDEQSソフトウェアでは、非正規分布をISO 22514-4の「統計的推定」に基づいて最もフィットする分布モデルを数学的に特定しています。選択された分布モデルからISO 22514-2に準拠したクオンタイル(分位点)算出を行って、6σ相当の範囲(99.73%)、つまり0.135%の分位点と99.865%の分位点1をソフトウェアで算出しています。
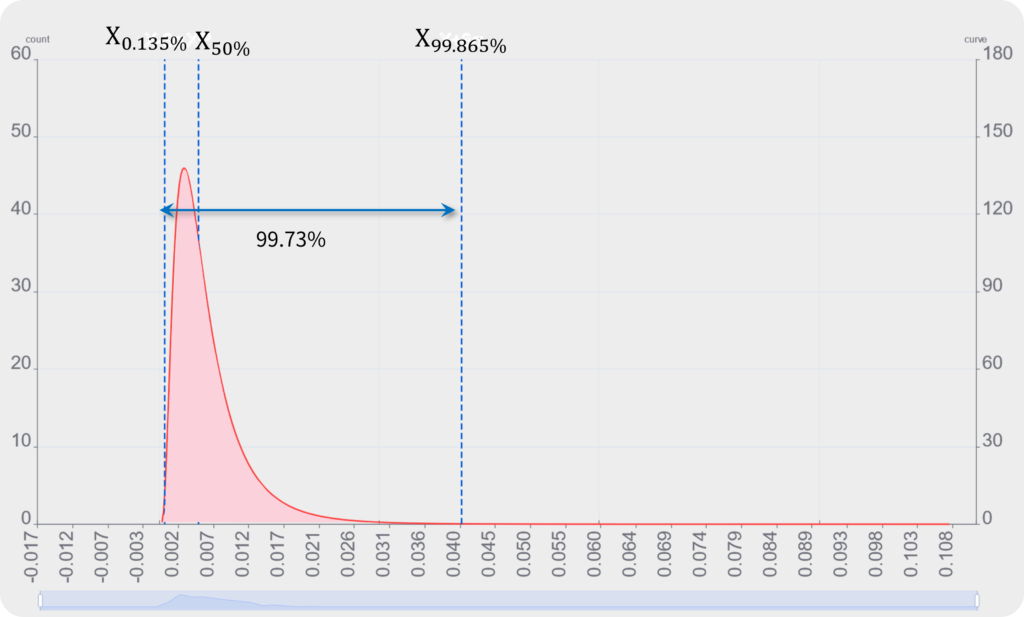
パーセンタイル表記の式に置き換え
非正規分布の場合、平均(μ)より外れ値に強い中央値を使うので、平均(σ)から中央値(パーセンタイル表記=X50%)に変更し、分布範囲(分母)の99.73%の部分をパーセンタイル法表記に変えるだけです。数字を入れ替えれるだけでCp/Cpkの基本的な数式が成り立ちます。
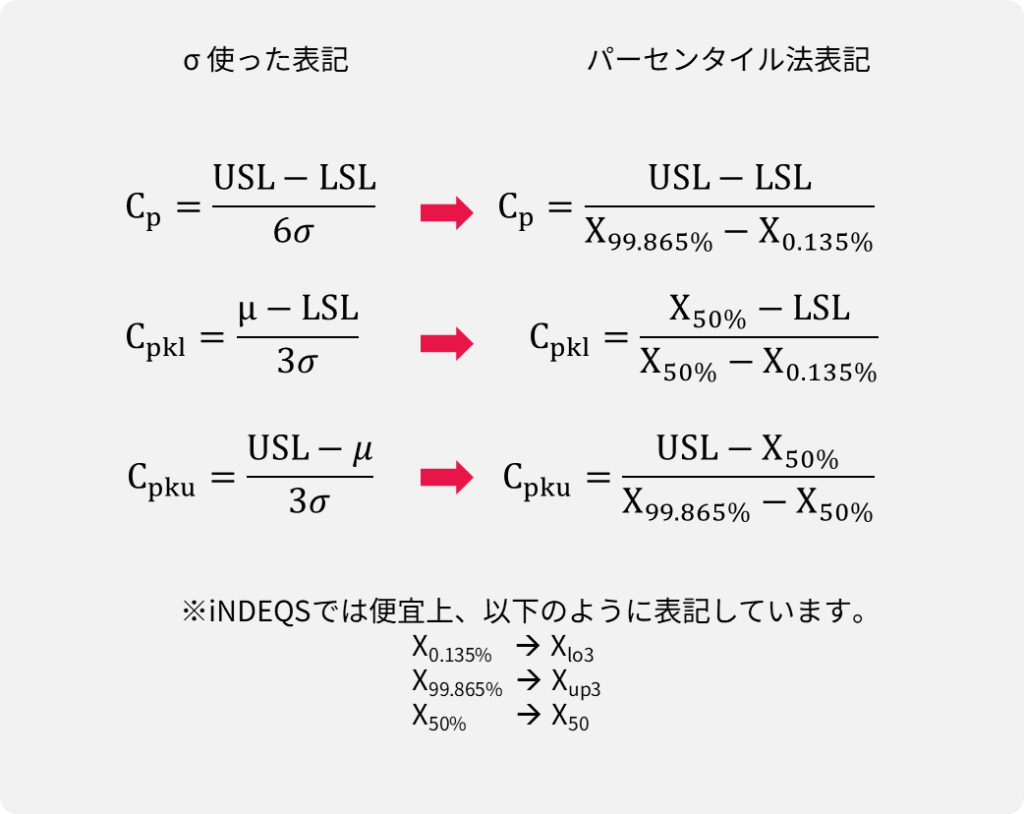
非正規分布評価の必要性
自然限界以外にも、短期的に正規分布となる特性も、長期間に亘って収集した工程データを評価すると殆どの場合、非正規分布になります。
工程変動の要因
短時間では安定している工程も、人、方法・手法、材料、設備、環境の「5M」の要因により変動します。
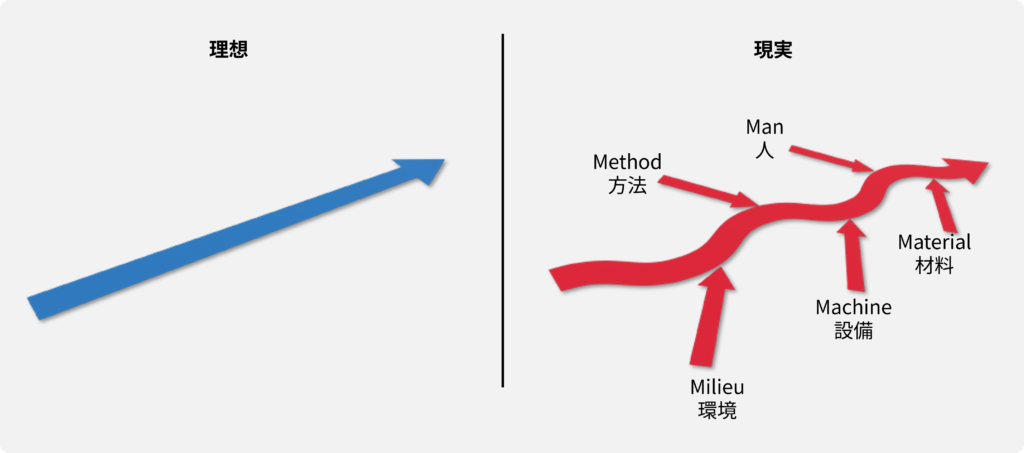
工程変動の要因
例えば、工程をより安定させるためには以下のような事が考えられます。
- 頻繁な機械調整
- 精密な温度調整
- 頻繁な測定機の校正
- 長期間の作業者トレーニング
しかしながら技術、時間、コストを考慮すると限界があり、最も経済合理性の高い状態を維持しつつ工程能力評価も行わなければならないため、非正規分布のままのデータも評価する必要があります。
↓EXCELでの計算に限界を感じたら↓
EXCELでの計算に限界を感じたら
専用ソフトウェアを使用する理由
学習目的の工程能力計算はEXCELを使って行う事も出来ますが、量産工程では殆どの場合専用ソフトウェアを使用せず実務を行うことは現実的ではありません。主な理由としては、
- 汎用表計算ソフトでは正規分布以外のデータは工程能力予測が困難
- 素早い「改善情報」の共有が必要
- 分析担当者が問題点を把握するだけでは改善アクションに繋がらない→素早い結果の共有が必要
- 5Mの要因ごとにデータの切口を変えた分析が可能
- 表計算ソフトはデータの切口を変える作業には不向き(データベース程の自由度と速度が無い)
- データ収集、分析を自動化する
- データ収集、分析に時間を取られてしまうと改善検討と実行の時間を十分に取れず生産性が上がらない
- 汎用の分析ソフトはある程度操作に習熟している担当者しか使えない
専用ソフトの最大のメリットは自動化とスピードです。データを収集し、分析を行って改善案を検討する事は重要ですが、実際には毎回汎用の分析ソフトを開いて、自分の担当工程のデータを抽出して分析して・・・とやっている時間はありません。一人の担当者が数百から数千の特性を管理しなければならない事もあります。この作業に時間を割いてしまうと、問題点が明らかになる前に、多数の不良品が流れてしまいます。
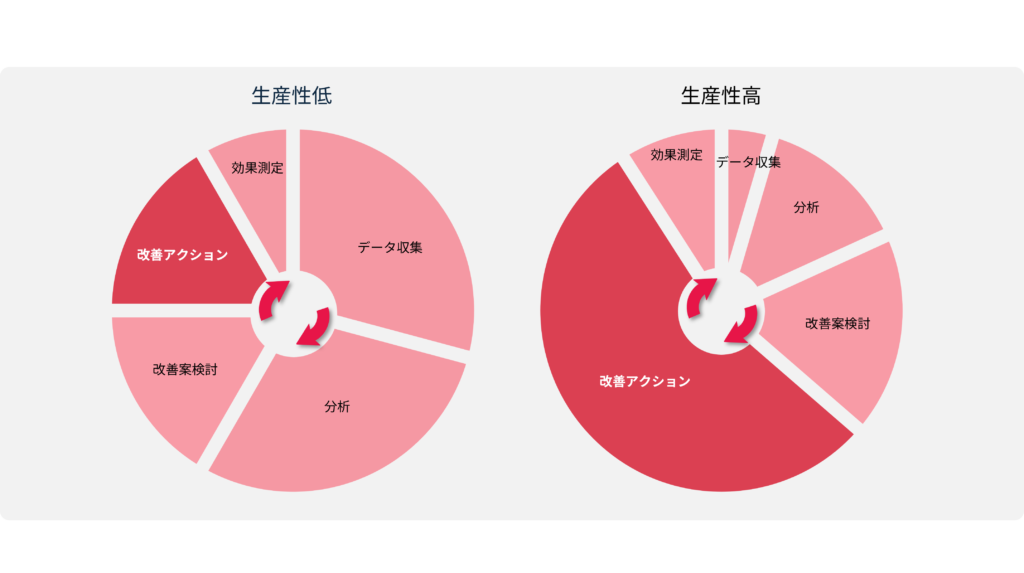
もう一つはソフトウェア操作の問題です。汎用の分析ソフトには強力な機能が付いているものが多く見られますが、結局使いこなせるのは日常ベースでソフトウェアを操作してる限られた担当者だけです。日常の分析には特別な操作を必要とせず、誰もが使える自動化されたツールが必要です。
工程の立ち上げ時には様々な分析を行うため、条件を細かく分けて不良率を計算したり、不良の原因究明を行う事も必要です。工程の立ち上げ時は、測定→分析→改善のPDCAサイクルを一旦立ち止まって行う事が出来るため、汎用のソフトでも対応できる範囲です。
しかし、実際は量産に入ってからの期間の方が圧倒的に長いのです。一旦自動化ラインが走り始めるとデータは加速度的に増加します。データベースから手動でデータを抽出し、ソフトウェアに展開して分析を行うためには、自席に戻ってPCを操作する必要があります。量産試作の段階で観測すべき項目と期間を見極めておき、公差外の抽出、工程能力計算、データの傾向監視等の手順を自動化して、実務にかける時間を増やす事で生産性の向上が見込めます。
弊社では工程立上げ時の分析には、細かく条件を変えて分析する事ができるi-Analyzerを使用を推奨しています。しかし一旦ラインが走り始めた後は煩雑な操作が不要なi-Boardを使って、汎用分析ソフトが苦手とする分析手順の自動化と、工程全体での品質情報のリアルタイム共有を実現しています。
- 分位点は形状をフィットさせる分布モデルにより異なります。INDEQSは自動でデータに合うと考えられる分布モデルの候補を幾つかフィッティングし、最も形状がフィットする分布曲線から百分位点(パーセンタイル値)を計算しています。 ↩︎